AI Infrastructure for Enterprise Intelligence
Build and scale any AI workloads on your own infra – document parsing, LLM finetuning, video embeddings, or run 70B Llama. Production in hours, not months.
Create your first AI workload with DAGPipe
Transform your code, models, and data sources into AI pipelines via simple configuration
Automate your LLM finetuning
Write the pipeline with the I/O data sources and Axolotl config. The A100s spins-up and run training in your infra automatically.
All the infra complexity, from GPU driver version mismatch, disk creation, firewalls ports taking care by the platform.
name = "qlora_finetuning"description = "Finetuning Llama-7B with Axolotl"job = { task_name="axolotl", profile="node_a100", mode="train" params = { config_text="config/lora8b-instruct.yml", },}input = 'gs://bucket/input'output = 'gs://bucket.output'Automate your data generation
Add the LLM models, notebook code and I/O into the pipeline. The VM with SGLANG run the models and code automatically.
You don't have to deal with SGLang installation, port access and others. Cut your time significantly.
name='generate_qa_llm'description='Generate data with GPT OSS 20B'cmd = 'python augmented.ipynb'startup = [{ name="sglang", model = "openai/gpt-oss-20b"}]input = 'gs://bucket/input'output = 'gs://bucket.output'Automate your inference
Write inference pipeline by define your models, job and compute resources. Kubernetes node GPU will created and run your inference.
No VLLM setup installation, No kubernetes manual creation. Everything done automatically.
name = "host_llm_inference"description = "Inferencing custom Llama-70B"job = { task_name="vllm", params = { model="llama-70b-finetuned", profile="medium_gpu" }}Automate your PDF extraction
Write pipeline with your I/O, code and docker image. The instance will be provisioned and run your code inside the docker automatically.
No docker setup, volume mounting, integration to GCS. Everything done by platform.
name = 'extract_pdf'description = 'Extract PDF to Markdown with Docling'image = 'docling:latest'cmd = "chmod +x run.sh && ./run.sh"input = 'gs://bucket/input'output = 'gs://bucket/output'compute = 'single_a100'Manage end-to-end AI pipelines, from raw data, training and serving
Each pipeline support parallel and chained dependencies across dedicated or shared compute resources
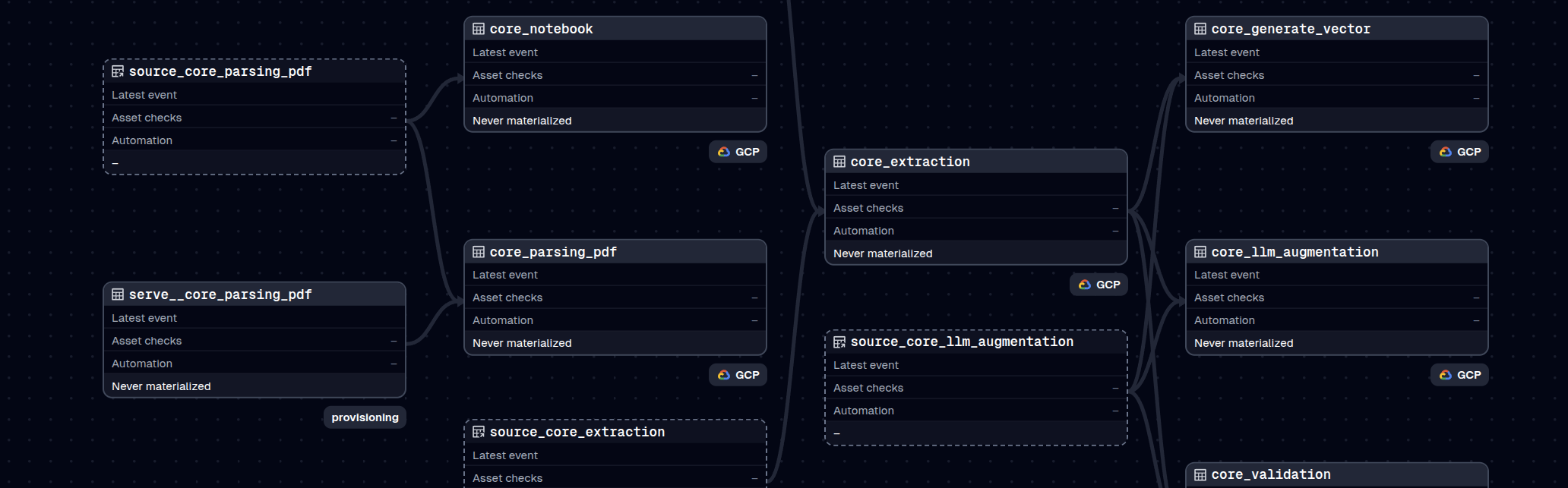
Manage and scale your compute infra with DAX
Automate provisioning single VM to multi-regional K8s clusters through a single YAML file.
Team collaboration
Spin a development server for AI workloads development inside organization private networks. Secured via IAP provides protection to internal data while working from public internet.
Features
- Real-time editor online collaboration
- Pipelines building with high compute
- Produce test environment
CLI Command
dax project deployConnect via IAP
gcloud compute ssh deploy --tunnel-through-iap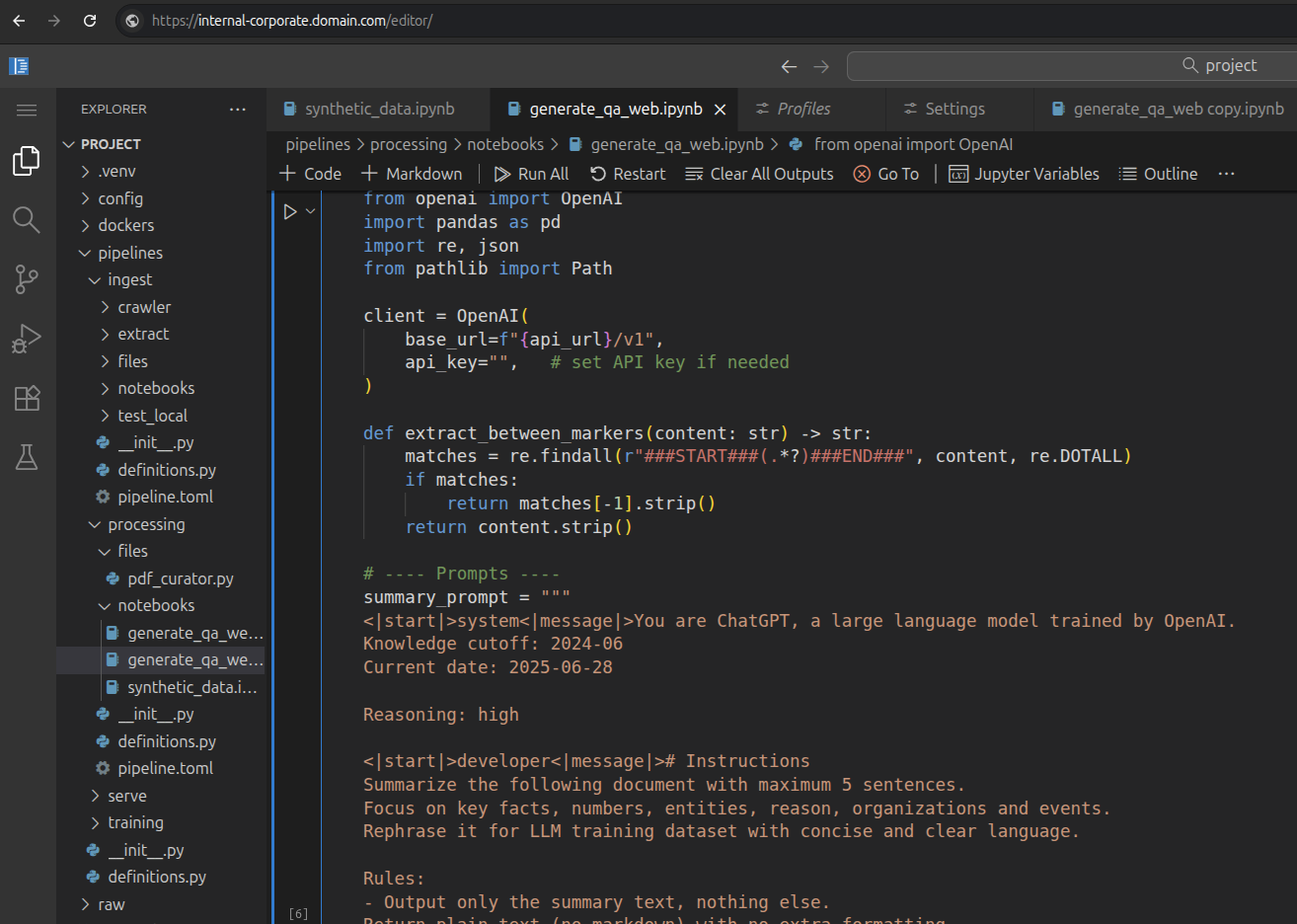
Infra config as YAML
Designed for repeatable deployment across teams and environments. Translating complex compute topologies into YAML-based components. Simplify complex infrastructure for LLM and data science pipelines with consistency and precision.
Features
- VM and Clusters support
- Spot / Preemptible options for cost savings
- Overrides configuration for more advanced usage
YAML configuration
gcp_vm_g2_16: machineType: g2-standard-16 gpu: 1 osImage: projects/cos-cloud/global/images/family/cos-121-lts preemptible: "true" provisioningModel: SPOT imageSize: 50 bootSize: 30 alternativeZones: - us-east1-b - us-central1-b
Scale with K8s clusters
Fully compatible with existing Kubernetes environments or deployable on demand through DAX. Support for Ray and native Kubernetes jobs provides flexibility for a wide range of workloads. Integrated gang scheduling ensures efficient GPU allocation for high-intensity AI tasks. Operational across GKE, on-premises deployments, and any standard Kubernetes cluster.
Features
- Cloud and On-premise clusters integration.
- Jobs via Ray, AppWrapper and Kubernetes.
- Gang-scheduling for GPU compute.
- More advanced features.
YAML configuration
apiVersion: kueue.x-k8s.io/v1beta1kind: ClusterQueuemetadata: name: "cluster-queue"spec: namespaceSelector: {} # match all namespaces resourceGroups: - coveredResources: [ "cpu", "memory", "ephemeral-storage" ] flavors: - name: "default-flavor" resources: - name: "cpu" nominalQuota: 10000 # Infinite quota. - name: "memory" nominalQuota: 10000Gi # Infinite quota. - name: "ephemeral-storage" nominalQuota: 10000Gi # Infinite quota.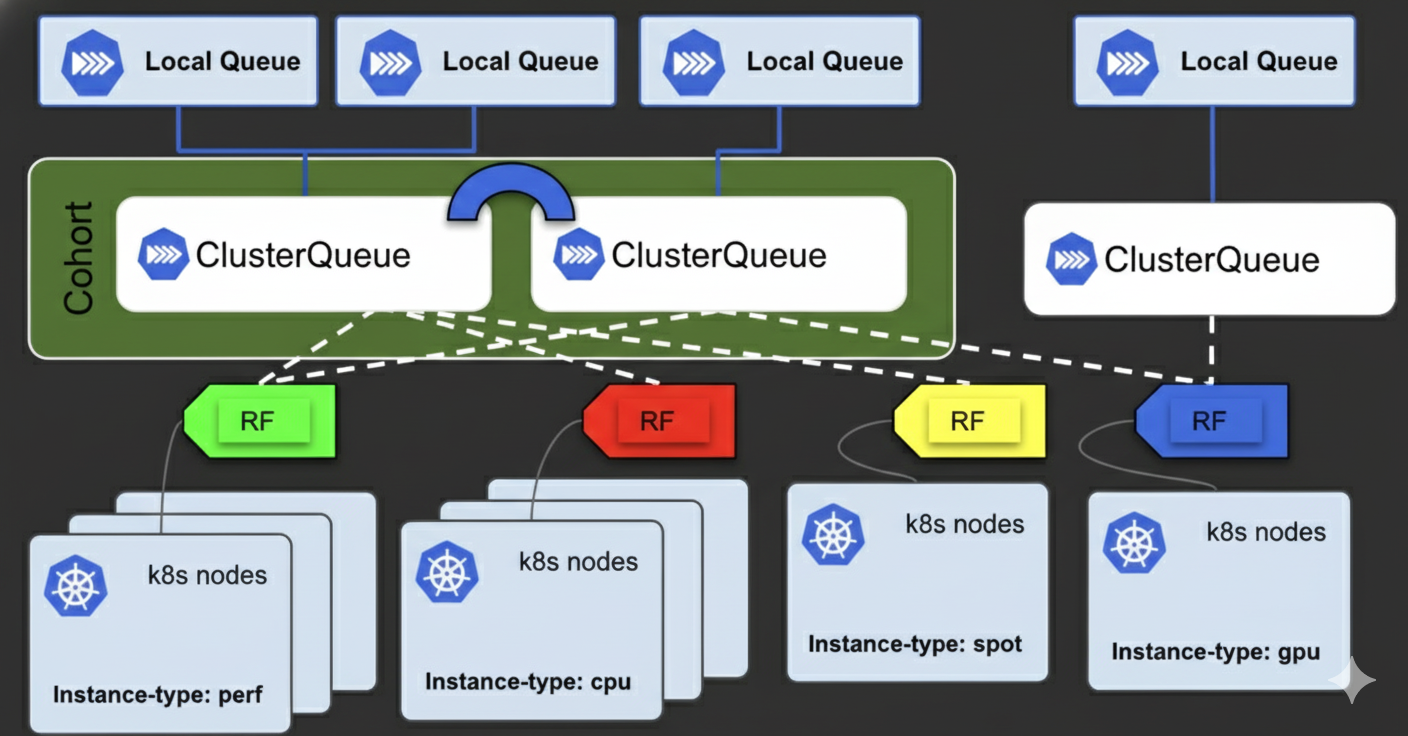
Favourites Features
- Container-basedRun any codes, tools and dataset inside docker image. Reduce drift issues between development and production environment.
- Cloud or Self-hostedUse DAX as control plane or runs on your own self hosted infra. Support VM-based and Kubernetes clusters for CPU + GPU.
- Enterprise SecurityBoth VM and Clusters on private network. Zero-trust policy with IAP integration. Hardened with Google Container Optimized OS technology.
- Deploy anywhereEnable heavy-lifting models training done with mobile internet and a laptop. No workstation required.
- Optimized for speedInfra provisioning in minutes, with auto-scaling, scheduler and disk caching works with air-gapped environment.
- CLI + API SupportAll complex operation done with simple command-line (CLI). Logs can be accessed via REST API logs.
FAQ
- A pipeline transforms input data into meaningful results — such as sharding large files, fine-tuning models, or running LLM evaluations. Modern LLM development relies on multiple interconnected pipelines: NeMo Curator for data preparation, Docling for extraction, Axolotl for training, and vLLM or SGLang for inference. Achieving seamless integration across these diverse tools and stages remains one of the big challenges in LLM development.
- Designing pipelines is one challenge; running them efficiently at scale is another. Even simple tasks like data augmentation with models such as Llama-70B demand significant compute — multi-core CPUs, high memory, multiple GPUs, and hundreds of gigabytes of storage. Running pipelines on distributed compute improves scalability but adds complexity, with challenges like network latency, GPU contention, driver mismatches, and unstable runtimes.
- Dagploy simplifies the entire lifecycle of AI pipelines — from creation to execution. It provides a unified system for defining workflows, provisioning compute across VMs or Kubernetes, and orchestrating GPU resources automatically. Dagploy eliminates manual setup and keeps your private LLM workloads reproducible, scalable, and secure. Its come with two offers: Daploy Pipelines and Dagploy Executor (DAX).
- A tool-agnostic pipeline builder that lets you bring any code, framework, or Docker image with custom commands and compute settings. Supports both sequential and parallel execution for flexible workflow design. Compatible with all languages (Python, Rust, etc.) and frameworks (Pandas, PyTorch, and more). Comes with a web interface to visualize, monitor, and manage pipelines in real time.
- A cloud orchestrator engine that ensures every pipeline runs reliably and efficiently. Supports both VM and Kubernetes-based computation, with optimizations like disk caching to reduce network overhead. Pipelines run under strict security standards — private network, IAP protection, and Container-Optimized OS. Configuration is defined through YAML or accessible via REST API and CLI, with auto-scaling and spot mode for cost efficiency.
- Yes. DAP and DAX provide scalable AI infrastructure for businesses of any size to train private LLMs with minimal setup, while ensuring all data remains fully secure within your own system.
- DAP is open-source, so you can use it right away without pay anything, while DAX is subscription-basis.
- Yes! There's plenty of information in the documentation.